




인텔, Xe3 그래픽 공개: Xe2 대비 50% 성능 향상·강화된 레이 트레이싱·12코어 iGPU 탑재


인텔의 Xe3 그래픽 아키텍처가 공식 발표되었으며, 먼저 Panther Lake의 내장 GPU(iGPU)에 적용되고 이후에는 Xe3P 변형 버전이 추가될 예정이다.
인텔, 3세대 Xe 그래픽 아키텍처 ‘Xe3’ 공개 — Panther Lake iGPU에 최대 50% 성능 향상, 추후 Xe3P 업그레이드 예정
지난해 인텔은 Xe2 아키텍처를 선보였으며, 이는 Lunar Lake ‘Core Ultra 200’ CPU의 내장 그래픽(iGPU)과 Arc B 시리즈 ‘Battlemage’ 외장 그래픽카드에 적용되었다. Xe2는 이전 세대 Xe1 아키텍처와 Arc Alchemist A 시리즈에서 얻은 경험을 바탕으로 두 플랫폼 모두에서 한층 완성도 높은 성능을 보여주며 성공적인 출시 사례로 평가받았다.



인텔은 소프트웨어 부문에서도 큰 발전을 이루어, 게이밍뿐 아니라 콘텐츠 제작, 렌더링, AI 작업까지 아우르는 우수한 드라이버 지원을 제공하고 있다. 최근 출시된 Arc Pro 시리즈 역시 Battlemage GPU와 동일한 드라이버 라인업에서 지원되고 있어, 인텔 그래픽 아키텍처 전반의 통합적 최적화가 이루어지고 있다.

지난 몇 달간의 흐름을 보면, 인텔은 그래픽 부문에서 꾸준히 안정적인 개선과 업데이트를 이어오고 있다.
아키텍처는 더 발전했고, 소프트웨어는 이를 더욱 효율적으로 최적화하고 성능을 끌어내는 역할을 하고 있다.
그리고 이제 곧 출시될 Panther Lake ‘Core Ultra 300’ 시리즈와 함께, 새로운 Xe 아키텍처 세대인 ‘Xe3’가 등장한다.
Xe3 iGPU = Arc B 시리즈 iGPU, 차세대 Xe3P도 예고
인텔은 Xe3를 통해 Xe2 아키텍처를 기반으로 그래픽 구조를 확장하고, **처리 효율 중심(throughput-optimized)**으로 설계된 새로운 디자인을 선보인다. 특히 **Xe3 내장 GPU(iGPU)**는 ‘Arc B 시리즈’ 브랜드로 통합된다.
한편, **Battlemage 외장 GPU(dGPU)**는 Xe2 아키텍처, Panther Lake iGPU는 Xe3 아키텍처를 기반으로 하지만,
인텔은 두 세대 간 구조적 유사점이 많기 때문에, 통합된 ‘Arc B 시리즈’ 제품 라인업으로 운영하기로 결정했다고 밝혔다.
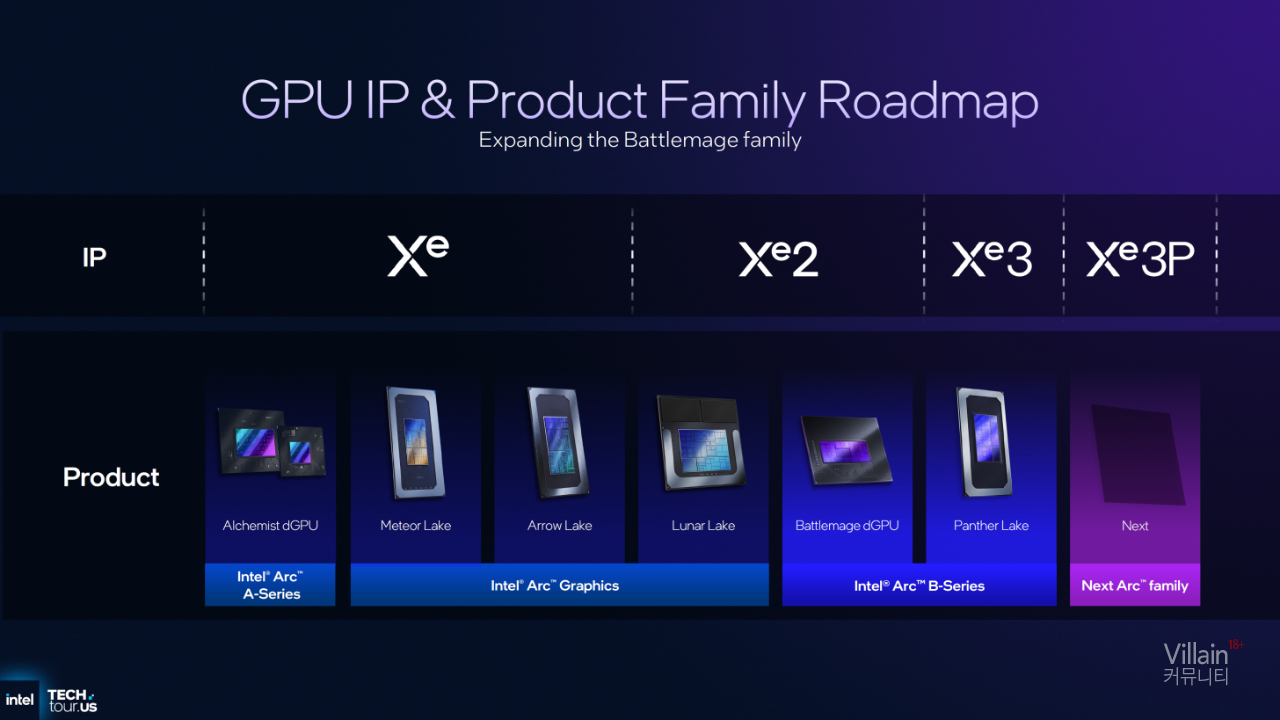
그렇다고 해서 인텔이 멈춘 것은 아니다. 이미 차세대 Arc 패밀리를 계획 중이며, 이 라인업에는 **업데이트된 Xe3 GPU 아키텍처인 ‘Xe3P’**가 탑재될 예정이다. Xe3P는 또 한 번의 큰 도약으로 평가되지만, 구체적인 세부 정보는 아직 공개되지 않았다.
현재로서는 인텔이 바로 Xe4로 넘어가기보다는, Xe3 아키텍처를 더욱 최적화하여 차세대 제품(내장·외장 GPU 모두)에 적용할 계획인 것으로 보인다. 실루엣 형태로 미루어볼 때 Xe3P는 외장형(dGPU)으로 구현될 가능성이 높지만, Nova Lake CPU의 고성능 iGPU 버전으로 적용될 수도 있다. 따라서 향후 공개될 정보를 주목할 필요가 있다.
또한 Xe3P GPU는 Battlemage dGPU나 Panther Lake iGPU처럼 Arc B 시리즈에 속하지 않으며, 다음 세대 Arc 제품군(아마도 Arc C 시리즈?)**에 포함될 예정이다. 이제 Xe3 아키텍처의 세부 내용으로 넘어가 보자.
Xe3 — 성능과 전력을 높이기 위한 iGPU 확장
새로운 Xe3 아키텍처에서 인텔이 가장 먼저 수행한 변화는 렌더 슬라이스(Render Slice) 확장이다.
기존 Xe2는 렌더 슬라이스당 4개의 Xe 코어와 4개의 레이 트레이싱(RT) 유닛으로 구성되어 있었다.

Xe3에서는 렌더 슬라이스당 Xe 코어와 레이 트레이싱(RT) 유닛 수가 6개로 확대되었다.
이는 각 렌더 슬라이스의 코어와 RT 유닛 수가 50% 증가한 것을 의미한다.

이를 통해 인텔은 Panther Lake SoC 내에서 다양한 GPU 타일 구성을 활용할 수 있게 되었다.
자세한 내용은 앞서 다룬 심층 분석에서 확인할 수 있다.
8코어(8C) 및 16코어(16C) 다이에는 4 Xe GPU 구성
최상위 16코어 다이에는 12 Xe GPU 구성
이는 흥미로운 비교가 될 전망이다. Arrow Lake와 Lunar Lake는 각각 Xe1, Xe2 아키텍처 기반으로 최대 8 Xe 코어를 탑재하고 있기 때문이다. Panther Lake는 8C와 16C SKU에서 4 Xe 코어만 사용하지만, 그래픽 아키텍처 개선 덕분에 경쟁력은 유지될 것으로 보인다.

이제 두 가지 구성 중 첫 번째, 4 Xe 코어 다이에 대해 살펴보자.
이 구성은 두 가지 버전으로 나뉜다.
8C 버전: 인텔의 ‘Intel 3’ 공정에서 제조
16C 버전: TSMC N3E 공정에서 제조
세부 구성은 다음과 같다:
Xe 코어: 4개 (Xe3 아키텍처)
렌더 슬라이스(Render Slice): 1개
XMX 엔진: 32개
L2 캐시: 4MB
지오메트리 파이프라인(Geo Pipeline): 1개
샘플러(Sampler): 4개
레이 트레이싱 유닛(RT Unit): 4개
픽셀 백엔드(Pixel Backend): 2개

12 Xe 코어 iGPU는 TSMC N3E 공정에서 제조된다.
12 Xe 코어 구성의 세부 사항은 다음과 같다:
Xe 코어: 12개 (Xe3 아키텍처)
렌더 슬라이스(Render Slice): 2개
XMX 엔진: 96개
L2 캐시: 16MB
지오메트리 파이프라인(Geo Pipeline): 2개
샘플러(Sampler): 12개
레이 트레이싱 유닛(RT Unit): 12개
픽셀 백엔드(Pixel Backend): 4개

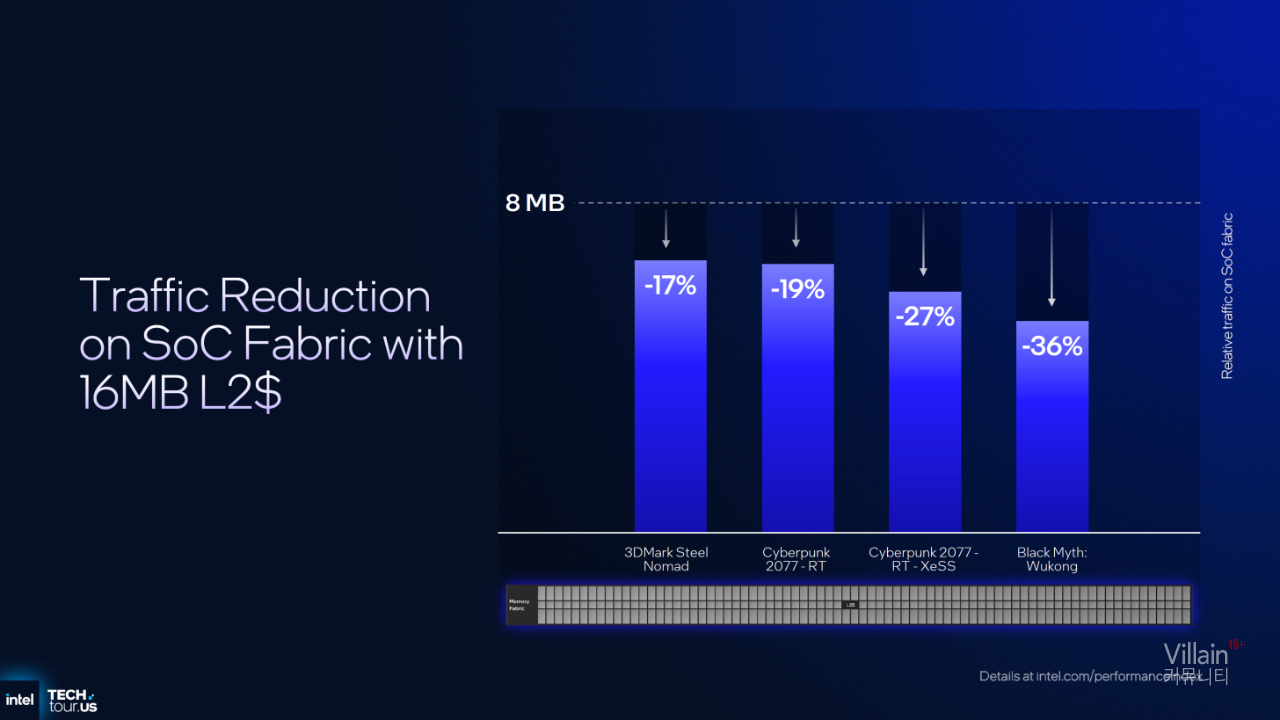
4 Xe 코어 iGPU 구성은 L2 캐시 4MB를 갖고 있어, Lunar Lake Xe2 iGPU의 8MB L2 캐시의 절반 수준이다.
반면, 최상위 12 Xe 코어 iGPU 구성은 L2 캐시가 두 배로 증가했다.
캐시 용량 증가 덕분에 SoC 패브릭 내 트래픽이 감소하며,
게임 시 최대 36% 트래픽 감소
평균적으로 약 25% 감소
효과를 볼 수 있다.
인텔 Xe3 아키텍처에서 구현된 주요 구조적 변화를 정리하면 다음과 같다.
Xe3 코어 구조
3세대 Xe 코어:
512비트 벡터 엔진(XVE) 8개
2048비트 XMX 엔진 8개
공유 L1/SLM 캐시 +33% 증가
Xe Vector Engine 특징:
Xe3 아키텍처에서 스레드 최대 25% 증가, 가변 레지스터 할당, FP8 디퀀타이제이션 지원
SIMD16 네이티브 ALU, 3-Way Co-Issue, 확장 수학 및 FP64 블록, Xe 매트릭스 확장 포함
Xe3 XMX 엔진 (AI 가속)
AI 성능: 12 Xe iGPU → 최대 120 TOPs, 4 Xe iGPU → 최대 40 TOPs
Xe2 8 Xe iGPU → 최대 67 TOPs
Xe3 8 Xe iGPU → 67 TOPs (25% 향상)
Per Xe-core ops/clock
TF32: 1024 ops/clk
FP16: 2048 ops/clk
BF16: 2048 ops/clk
INT8: 4096 ops/clk
INT4/INT2: 8192 ops/clk
레이 트레이싱(RT) 유닛 개선
동적 레이 관리(Dynamic Ray Management) 적용, 비동기 레이 트레이싱 지원
트래버설 파이프라인, 삼각형 교차 유닛 2개, BVH 캐시 포함
스레드 정렬 유닛을 통한 파이프라인 병목 방지
그래픽 고정 기능 향상
URB 관리자: 전체 갱신 대신 부분 갱신 가능
이방성 필터링 최대 2배 향상
스텐실 테스트 최대 2배 향상
미디어 엔진
AV1 인코딩/디코딩, VVC 디코딩 지원
eDP 1.5 지원
AVC 10비트, Sony XAVC-H/HS/S 지원
성능 향상
Xe3 마이크로벤치마크: Blend/Backend 거의 변화 없음, FP16(GEMM) 50% 향상
이방성 필터링, Mesh Render, Scattered Reads, R/T Intersection 2~2.7배 향상
Depth Testing, Register Heavy 앱 7배 이상 성능 향상
실제 성능:
Lunar Lake(Xe2) 대비 50% 이상 성능 향상
Arrow Lake-H 대비 전력당 성능 40% 이상 향상
소프트웨어 최적화
Windows Graphics Stack 개선: IGC 컴파일러 업데이트, 가변 레지스터 할당 개선
**직접 선점(Direct Preemption)**으로 컨텍스트 전환 시 플러시 없이 처리
DirectX Cooperative Vectors 지원
Neural Radiance Field 데모에서 Cooperative Vectors 활용
종합 평가
Xe3 iGPU는 기존 Xe2 대비 강력한 업그레이드
Xe2는 Radeon 890M, 880M 같은 RDNA 3.5 iGPU 수준과 비슷
Xe3는 향후 Intel+NVIDIA 맞춤형 SoC와 결합 시 고성능 시장까지 커버 가능
출처 : https://wccftech.com/intel-xe3-graphics-official-50-percent-faster-than-xe2-xe3p-next-gen-arc-family/
TAG



 0 / 0
0 / 0


 마이크로닉스
@micronics
1일전
마이크로닉스
@micronics
1일전









- 이벤트 l
- 체험단 모집 l
- 특가 이벤트 l
- 당첨/발표
- [체험단 모집] 맥스엘리트 850W 파워 체험단 모집
-
2026.01.21
 6
6
 4
4
- [특가 이벤트] 잘만, HPS800W 무선 헤드셋 및 HPS610 헤드셋 특가 및 포토리뷰 이벤트
-
2026.05.26
0
0
- [특가 이벤트] 크록스 스프링 페스타 3월 18일, 최대 6만원 추가 할인
-
2026.03.16
1
1
- [특가 이벤트] 3/3(화) 오후 8시, UP TO 50% + 라이브 단독 1만원 추가 할인
-
2026.03.02
0
0
- [특가 이벤트] 크록스 코리아 남성 BEST 클로그 5% 쿠폰 혜택
-
2026.02.26
0
1
- [당첨/발표] [발표] 댓글학원 우등생 TOP 5 발표
-
2026.07.22
8
5
- [당첨/발표] [발표] AI에이전트 미니PC지원 댓글이벤트 당첨자 발표
-
2026.04.06
6
3
- [당첨/발표] 맥스엘리트 850W 체험단 당첨자 발표
-
2026.02.02
3
2
- [당첨/발표] 1월 베스트 빌런 댓글러 이벤트 당첨자 발표
-
2026.02.02
5
3
- [당첨/발표] 1월 신규가입자 이벤트 당첨자 발표
-
2026.02.02
5
2


- 종합
- 뉴스/정보
- 커뮤니티
- 질문/토론

















