




NVIDIA, Nemotron 3 공개

나노·슈퍼·울트라 3종 구성… Nemotron 2 대비 최대 4배 빠른 성능
NVIDIA가 최신 개방형 AI 모델 패밀리인 Nemotron 3를 공개했다. Nemotron 3는 나노, 슈퍼, 울트라 세 가지 크기로 구성되며, 멀티 에이전트 AI를 대규모로 구축하고 운영할 수 있도록 설계된 것이 특징이다. NVIDIA는 Nemotron 3가 이전 세대인 Nemotron 2 대비 최대 4배 빠른 토큰 처리 성능을 제공한다고 밝혔다.
Nemotron 3는 하이브리드 잠재 혼합 전문가 구조, 즉 MoE 기반 아키텍처를 도입해 효율성과 정확도를 동시에 높였다. 이를 통해 투명하고 특화된 에이전트형 AI를 다양한 산업 환경에서 구현할 수 있다는 설명이다. NVIDIA는 이 모델이 자사 소버린 AI 전략의 핵심 축으로, 각국 기관과 기업이 자국 데이터와 규제, 가치관에 맞는 AI 시스템을 구축할 수 있도록 돕는다고 강조했다.

Nemotron 3 제품군은 세 가지 모델로 나뉜다.
나노는 총 300억 파라미터 가운데 30억 파라미터가 활성화되는 소형 모델로, 특정 작업에 최적화된 고효율 모델이다.
슈퍼는 약 1000억 파라미터 가운데 100억이 활성화되는 고정확도 추론 모델로, 다수의 에이전트가 협력하는 환경에 적합하다.
울트라는 약 5000억 파라미터 가운데 500억이 활성화되는 대형 추론 엔진으로, 복잡한 연구와 전략 수립이 필요한 AI 워크플로를 겨냥한다.
현재 즉시 사용 가능한 모델은 Nemotron 3 나노다. 이 모델은 소프트웨어 디버깅, 콘텐츠 요약, AI 어시스턴트, 정보 검색과 같은 작업에서 낮은 추론 비용으로 높은 성능을 제공하도록 설계됐다. Nemotron 2 나노 대비 토큰 처리량은 최대 4배 증가했고, 추론 토큰 생성량은 최대 60퍼센트 감소해 비용 효율성이 크게 개선됐다. 문맥 길이는 최대 100만 토큰을 지원해, 장시간에 걸친 복합 작업에서도 정보 연결 능력이 강화됐다.
독립 AI 벤치마킹 기관인 Artificial Analysis는 Nemotron 3 나노를 동급 모델 가운데 가장 개방적이면서 효율적인 모델로 평가했으며, 정확도 역시 상위권으로 분류했다.
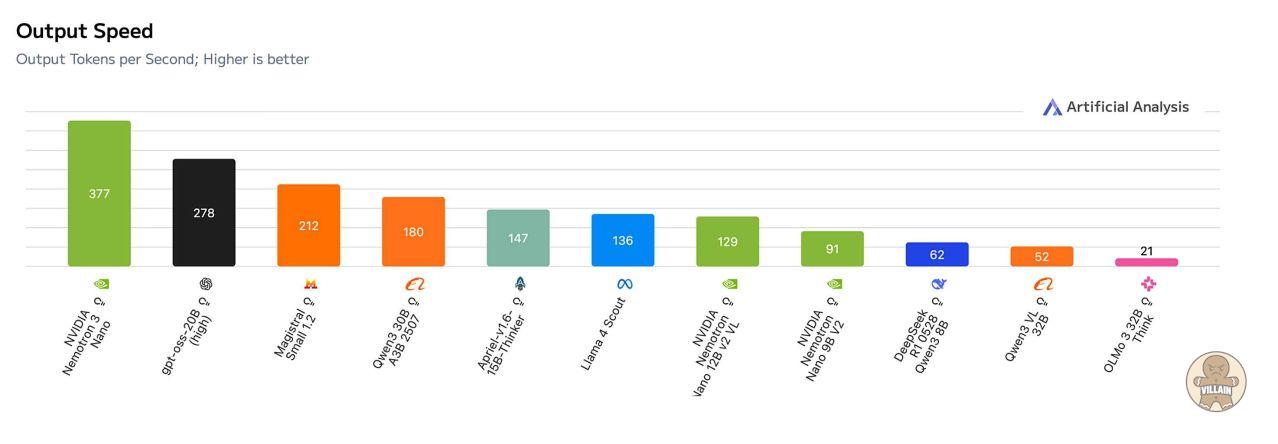
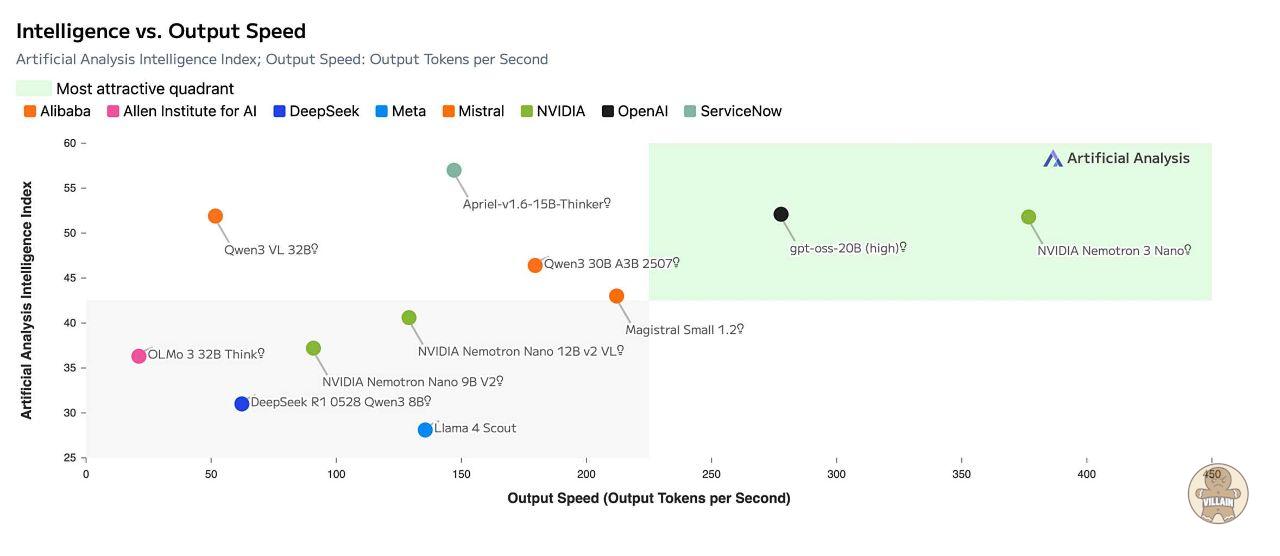
Nemotron 3 슈퍼와 울트라는 NVIDIA 블랙웰 아키텍처에서 4비트 NVFP4 학습 포맷을 사용한다. 이를 통해 메모리 요구량을 크게 줄이면서도, 고정밀 포맷 대비 정확도 손실 없이 학습 속도를 높일 수 있다는 설명이다. 이 방식 덕분에 기존 인프라에서도 훨씬 대형 모델을 효율적으로 학습할 수 있다.
Nemotron 3는 이미 다양한 기업 환경에 도입되고 있다. 액센츄어, 캐던스, 크라우드스트라이크, 커서, 딜로이트, EY, 오라클 클라우드 인프라스트럭처, 팔란티어, 퍼플렉시티, 서비스나우, 지멘스, 줌 등이 Nemotron 계열 모델을 활용해 제조, 사이버보안, 소프트웨어 개발, 미디어, 커뮤니케이션 분야의 AI 워크플로를 강화하고 있다. 스타트업 역시 Nemotron 3를 기반으로 AI 에이전트를 빠르게 개발하고 기업 환경으로 확장하고 있다.
Nemotron 3 나노는 현재 허깅페이스를 비롯해 Baseten, Deepinfra, Fireworks, FriendliAI, OpenRouter, Together AI 등 여러 추론 서비스에서 제공된다. 또한 AWS의 아마존 베드록을 포함해 구글 클라우드, 코어위브, 네비우스, 엔스케일, 요타 등에서도 순차적으로 지원될 예정이다. 기업 환경에서는 NVIDIA NIM 마이크로서비스 형태로 제공돼, NVIDIA 가속 인프라 위에서 보안과 확장성을 확보한 배포가 가능하다.
Nemotron 3 슈퍼와 울트라는 2026년 상반기 중 제공될 예정이다. NVIDIA는 Nemotron 3를 통해 개발자가 작업 규모에 맞는 개방형 모델을 선택하고, 수십에서 수백 개의 에이전트로 확장 가능한 고속 추론과 장기적 사고가 필요한 복잡한 워크플로를 구현할 수 있다고 강조했다.



 0 / 0
0 / 0




 다크플래쉬
@darkflash
13시간전
다크플래쉬
@darkflash
13시간전









- 이벤트 l
- 체험단 모집 l
- 특가 이벤트 l
- 당첨/발표
- [체험단 모집] 맥스엘리트 850W 파워 체험단 모집
-
2026.01.21
 6
6
 4
4
- [특가 이벤트] 잘만, HPS800W 무선 헤드셋 및 HPS610 헤드셋 특가 및 포토리뷰 이벤트
-
2026.05.26
0
0
- [특가 이벤트] 크록스 스프링 페스타 3월 18일, 최대 6만원 추가 할인
-
2026.03.16
1
1
- [특가 이벤트] 3/3(화) 오후 8시, UP TO 50% + 라이브 단독 1만원 추가 할인
-
2026.03.02
0
0
- [특가 이벤트] 크록스 코리아 남성 BEST 클로그 5% 쿠폰 혜택
-
2026.02.26
0
1
- [당첨/발표] [발표] AI에이전트 미니PC지원 댓글이벤트 당첨자 발표
-
2026.04.06
6
3
- [당첨/발표] 맥스엘리트 850W 체험단 당첨자 발표
-
2026.02.02
3
2
- [당첨/발표] 1월 베스트 빌런 댓글러 이벤트 당첨자 발표
-
2026.02.02
5
3
- [당첨/발표] 1월 신규가입자 이벤트 당첨자 발표
-
2026.02.02
5
2
- [당첨/발표] 인사이 댓글 이벤트 당첨자발표
-
2026.01.26
6
4


- 종합
- 뉴스/정보
- 커뮤니티
- 질문/토론



















